
人们凭直觉认为,我们非常擅长自己创造出的游戏,但计算机一次又一次地证明,人类的速度还不够快,无法稳居宝座。机器不但在国际象棋在中击败了我们,甚至拿下了非常复杂的围棋。谷歌刚刚凭借AlphaGo获得了殊荣,却又一次创造了神话。仅仅18个月后,DeepMind的人工智能击败了最优秀的《星际争霸2》职业玩家,且二者实力相去甚远。
DeepMind将围棋人工智能称为AlphaGo,而给此次参与《星际争霸2》的人工智能,实验室依样称其为AlphaStar。论AlphaStar的训练强度,相当于已经打了200年的实战。AlphaStar是一种卷积神经网络。实验室首先回放职业比赛,让AlphaStar理解比赛如何开赛。通过在对抗模式下进行密集训练,DeepMind能够教会AlphaStar如何打比赛,告诉它哪些是优秀的职业玩家。随着时间推移,AlphaStar将会把学习范围缩小至五名最优秀的玩家身上,这也是它对抗《星际争霸2》职业玩家的方式。
比赛实际上是在去年12月进行的,所以今天互联网上流传的大多是先前比赛的回放。首先,AlphaStar与玩家TLO进行作战,虽然玩家惯常以虫族角色打比赛,但由于AlphaStar只进行了特定角色的训练,所以TLO必须打神族角色。这场比赛实力悬殊,尽管TLO尽了最大的努力,AlphaStar还是以5:0的成绩击败了他。接下来,AlphaStar与另一名经验丰富的神族玩家MaNa进行对决。虽然其中几场比赛MaNa还有希望,但AlphaStar最终也以5:0的比分获胜。而后MaNa要求再赛一局,同时抓住了AlphaStar的缺陷,因而拿下了加赛的一局。
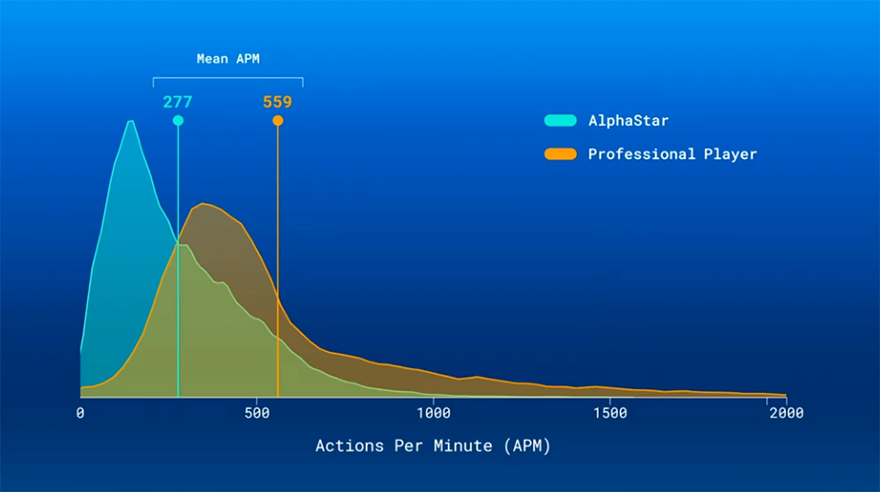
在整场比赛中,AlphaStar展示了令人印象深刻的微观管理(Micromanagement)能力。它能迅速将受损部队移回,将更强的部队移入战斗前线。AlphaStar还控制了战斗的节奏,在适当的时间让部队前进,并在合适的时机撤退,以此减少伤害。这和每分钟操作数(Actions Per Minute,下文简称APM)无关,因为AlphaStar的APM其实比职业玩家低很多,但是它能够做出更明智的选择。
AlphaStar也有一些有趣的战略癖好,它经常让部队在坡道上冲锋,但这在《星际争霸2》中是很危险的选择,因为在向上冲时视野是受限的。但不知何故,AlphaStar的这一策略也发挥了作用。职业玩家经常使用建筑墙来封锁基地坡道,但AlphaStar并没有采取这一战术。
直到最后一场比赛,职业玩家MaNa才发现 AlphaStar的缺陷,也就是它习惯整体移动部队,集中攻打MaNa的基地。不过,MaNa只要在AlphaStar的基地后面的传送几支部队,那么AlphaStar就会立刻调转方向应对威胁,如此反复就给了MaNa足够的时间来组建更强大的力量,瓦解AlphaStar的攻击。AlphaStar在与职业玩家的比赛中赢得了10场比赛,只输了1场。如果AlphaStar从这一场输掉的比赛中吸取教训,那么未来它可能战无不胜。




