
让我们看看 AlphaStar 究竟哪里“作弊”了,以下为机器之心对该文章的编译介绍:
首先,我必须声明我是门外汉。最近我一直追踪 AI 发展和星际争霸 2,不过我在这两个领域都不是专家。如有错漏,请见谅。其次,AlphaStar 确实是一项巨大成就,我很期待看到它以后的发展。
AlphaStar 的超人速度
AlphaStar 团队领导 David Silver:“AlphaStar 不能比人类选手反应速度快,也不会比人类选手执行更多点击。”
2018 年,来自芬兰的虫族选手“Serral”Joona Sotala 制霸星际 2。他是目前的世界冠军,且他在当年的九场大型赛事中取得了七次冠军,在星际 2 历史上是史无前例的选手。他的操作速度非常快,可能是世界上最快的星际 2 选手。

在 WCS2018 上,Serral 的毒爆虫让局势逆转。
在比赛中,我们可以看到 Serral 的 APM(actions per minute)。APM 基本上表示选手点击鼠标和键盘的速度。Serral 无法长时间保持 500 APM。视频中有一次 800 APM 的爆发,但只持续了一秒,而且很可能是因为无效点击。
世界上速度最快的人类选手能够保持 500 APM 已经很不错了,而 AlphaStar 一度飙到 1500+。这种非人类的 1000+ APM 的速度竟然持续了 5 秒,而且都是有意义的动作。一分钟 1500 个动作意味着一秒 25 个动作。人类是无法做到的。我还要提醒大家,在星际 2 这样的游戏中,5 秒是很长一段时间,尤其是在大战的开始。如果比赛前 5 秒的超人执行速度使 AI 占了上风,那么它以大幅领先优势获取胜利可能是由于雪球效应。
一位解说指出平均 APM 仍是可接受的,但很明显这种持续时间并非人类所能为。
AlphaStar 的无效点击、APM 和外科手术般的精准打击
大部分人类都会出现无效点击。无意义的点击并没有什么用。例如,人类选手在移动军队时,可能会点击目的地不止一次。这有什么作用呢?并没有。军队不会因为你多点击了几下就走得更快。那么人类为什么还要多点击呢?原因如下:
1. 无效点击是人类想要加快操作速度的自然结果。
2. 帮助活跃手指肌肉。
我们前面说过 Serral 最令人震惊的不是他的速度而是准确度。Serral 不只是具备高 APM,还具备非常高的 effective-APM(下文中简略为 EAPM),即仅将有效动作计算在内的 APM。
一位前职业玩家在看到 Serral 的 EAPM 后发推表示震惊:
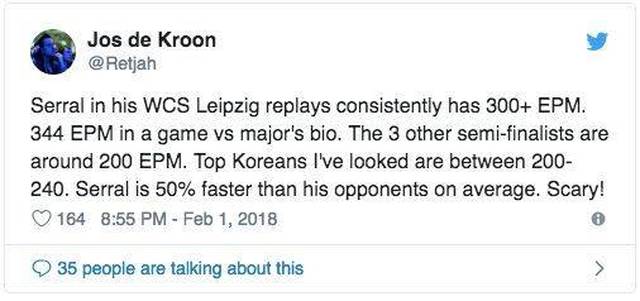
Serral 的 EAPM 是 344,这实际上已经是前所未有了。APM 和 EAPM 的区别也涉及 AlphaStar。如果 AlphaStar 没有无效动作,这是不是说明它的巅峰 EAPM 等于巅峰 APM?这样的话 1000+的爆发更加非人类了。我们还需要考虑 AlphaStar 具备完美的准确率,它的性能好到“荒谬”的程度。它总能点击到想去的地方,而人类会有误点击。AlphaStar 可能不会一直使用巅峰状态,但在关键时刻,它的速度是世界最快选手的 4 倍,而准确率更是人类专业玩家想都不敢想的。星际 2 中存在一个共识:AlphaStar 的执行序列人类无法复制。其速度和准确率突破了人类现有极限。
AlphaStar 只能执行人类选手可以复制的动作?David Silver 不认同这种看法。
正确做事 vs 快速做事
AlphaStar 的首席设计工程师 Oriol Vinyals:
我们正在努力构建拥有人类惊人学习能力的智能系统,因此确实需要让我们的系统以尽可能“像人类一样”的方式学习。例如,通过非常高的 APM,将游戏推向极限可能听起来很酷,但这并不能真正帮助我们衡量智能体的能力和进步,使得基准测试毫无用处。
为什么 DeepMind 想限制智能体像人类一样玩游戏?为什么不让它放飞自我?原因是星际争霸 2 是一个可以通过完美操作攻破的游戏。在这个 2011 年的视频(https://www.youtube.com/watch?v=IKVFZ28ybQs)中,AI 攻击一组坦克,其中一些小狗实现了完美的微操。例如,在受到坦克攻击时让周围的小狗都躲开。

通常情况下,小狗不能对坦克做出太大 伤害,但由于 AI 完美的微操,它们变得更加致命,能够以最小的损失摧毁坦克。当单元控制足够好时,AI 甚至不需要学习策略。而在没有这种微操时,100 只小狗冲进 20 架坦克中只能摧毁两架坦克。

并不一定对创建可以简单击败星际争霸专业玩家的 AI 感兴趣,而是希望将这个项目作为推进整个 AI 研究的垫脚石。虽然这个研究项目的重要成员声称具有人类极限限制,但事实上智能体非常明显地打破了这些限制,尤其是当它利用超人速度的操作来赢得游戏时,这是完全无法让人满意的。
AlphaStar 能够在单位控制方面超越人类玩家,当游戏开发者仔细平衡游戏时,肯定不会去考虑这一点。这种非人类级别的控制可以模糊人工智能学习的任何战略思维评估。它甚至可以使战略思维变得完全没有必要。这与陷入局部极大值不同。当 AI 以非人类级别的速度和准确率玩游戏时,滥用卓越的控制能力很可能变成了玩游戏时的最佳策略,这听起来有些令人失望。
这是专业人士在以 1-5 的比分输掉比赛之后所说的 AI 优点和缺点:
MaNa:它最强的地方显然是单位控制。在双方兵力数量相当的情况下,人工智能赢得了所有比赛。在仅有的几场比赛中我们能够看到的缺点是它对于技术的顽固态度。AlphaStar 有信心赢得战术上的胜利,却几乎没有做任何其它事情,最终在现场比赛中也没有获得胜利。我没有看到太多决策的迹象,所以我说人工智能是在靠操作获得胜利。
在 DeepMind 的 Replay 讲解和现场比赛之后,星际争霸玩家群体几乎一致认为 AlphaStar 几乎完全是因为超人的速度、反应时间和准确性而获得优势的。与之对抗的职业选手似乎也同意。有一个 DeepMind 团队的成员在职业玩家测试它之前与 AlphaStar 进行了比赛。他估计也同意这种观点。David Silver 和 Oriol Vinyal 不断重复声称 AlphaStar 如何能够完成人类可以做的事情,但正如我们已经看到的那样,这根本不是真的。
在这个视频中关于“AlphaStar 如何能够完成人类可以做的事情”的描述非常粗略。
为什么 DeepMind 允许 AlphaStar 拥有超人的操作能力
1)在项目一开始,DeepMind 同意对 AlphaStar 施加严格的 APM 限制。因此 AI 不会在演示中出现超人的操作速度。如果让我来设计这些限制,可能包含如下几项:
2)接下来,DeepMind 会下载数以千计高排名的业余游戏视频并开始模仿学习。在这个阶段,智能体只是试图模仿人类在游戏中所做的事情。
3)智能体采用无效点击的行为。这很可能是因为人类玩家在游戏过程中使用了这种点击行为。几乎可以肯定,这是人类执行的最单调重复的行为模式,因此很可能深深扎根于智能体的行为中。




