“击败星际争霸II职业玩家”的AlphaStar是在作弊?(2)
时间:2019-01-30 20:56 来源:百度新闻 作者:巧天工 点击:次
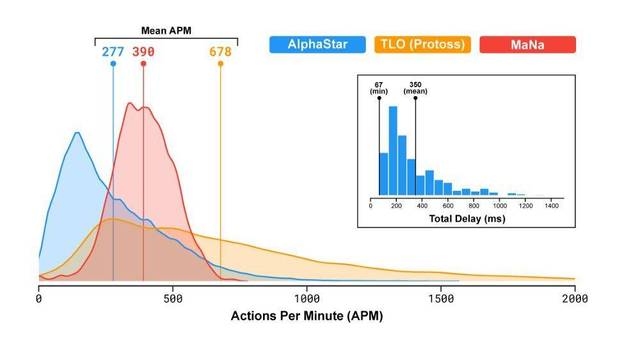
4)AlphaStar 爆发的最大 APM 受限于人类进行无效点击的速度。由于 AlphaStar 执行的大多数操作都是无效点击,因此没有足够的 APM 可用于在战斗中进行实验。如果智能体未进行实验,则无法学习。以下是其中一位开发人员昨天在 AMA 上所说的话: AlphaStar 的首席设计工程师 Oriol Vinyals:训练人工智能玩低 APM 非常有趣。在早期,我们让智能体以非常低的 APM 进行训练,但它们根本没有微操。 5)为了加速开发,他们改变 APM 限制以允许高速爆发。以下是 AlphaStar 在演示中使用的 APM 限制: AlphaStar 的首席设计工程师 Oriol Vinyals:尤其是,我们在 5 秒的时间段内设置的最大 APM 为 600,在 15 秒内最大为 400,30 秒内最大为 320,在 60 秒内最大为 300。如果智能体在此期间执行更多的操作,我们会删除/忽略这些操作。这些是根据人类统计数据设置的。 人类进行无效点击的速度是有限的。最典型的无效点击形式是对一个单位发出移动或攻击命令。这是通过用鼠标点击地图某个位置来完成的。请尽你最快的速度点击鼠标试试。智能体学会了这种无效点击。它不会点击地太快,因为它模仿的人类无法点击太快。而能让它达到超人速度的额外 APM 可以被认为是“自由的”APM,它可以用于更多次尝试。 6)自由的 APM 被用于在交战中进行实验。这种交互在训练中经常发生。AlphaStar 开始学习新的行为以带来更好的结果,它开始摆脱经常发生的无效点击。 7)如果智能体学会了真正有用的动作,为什么 DeepMind 不回到最初对 APM 更苛刻、更人性化的限制呢?他们肯定意识到了其智能体正在执行超人的动作。星际社区一致认为 AlphaStar 拥有超人的微操技术。人类专家在 ama 中表示,AlphaStar 的最大优势不是其单位控制,而其最大的弱点也不是战略思维。DeepMind 团队中玩星际的人肯定也是这么想的,理由是因为智能体偶尔还是会进行无效点击。 虽然在玩游戏的大部分时间里,它能直接执行有效动作,但它还是经常做无效点击。这一点在它与 MaNa 的比赛中很明显,该智能体在 800APM 上无意义地点击移动命令。尽管这完全没必要,而且消耗了它的 APM 资源,但它仍不忘记这么干。无效点击会在大规模战争中对智能体造成很大伤害,它的 APM 上限可能会被修改以使它在这些对抗中表现良好。 不要在意这些细节? 现在你明白是怎么回事儿了。我甚至怀疑人工智能无法忘记它在模仿人类玩家过程中学习到的无效点击行为,因而 DeepMind 不得不修改 APM 上限以允许实验进行。这么做的缺点就是人工智能有了超越人类能力的操作次数,从而导致 AI 以超越人类的手速,不用战术战略就能打败人类。 我们对 APM 如此关心,是因为 DeepMind 击败人类职业玩家的方式与他们所希望的方式,以及所声称的“正确”方式完全相反。而 DeepMind 放出的游戏 APM 统计图也让我们对此有所洞悉:
这种统计方式似乎是在误导不熟悉星际争霸 2 的人。它似乎在把 AlphaStar 的 APM 描述为合理的。我们可以看看 MaNa 的数据,尽管他的 APM 均值比 AlphaStar 要高,但在最高值上 AI 远高于人类,更不用说在高 APM 时人类操作的有效性了。请注意:MaNa 的峰值是 750,而 AlphaStar 高于 1500。想象一下,MaNa 的 750 包含 50% 的无效点击,而 AlphaStar 的 EAPM 几乎完美…… 至于 TLO 的“逆天”手速,星际争霸主播黄旭东和孙一峰在直播时认为他明显使用了加速键盘(通过特殊品牌的键盘热键功能,设置某单个快捷键/组合键代替多次鼠标点击)。
加速键盘可以让人类的 APM 达到不可理喻的高度,比如 15,000 多――但并不会提升你的有效操作。 然而,你用加速键盘能做的唯一一件事就是无效施法。出于某些莫名的原因,TLO 在滥用这个技术,这种操作的统计结果让不熟悉星际争霸的人看起来好像 AlphaStar 的 APM 是在合理范围之内的。DeepMind 的介绍性博客并没有提到 TLO 荒谬数字的原因,如果没有解释,这个数字就不应该被列在图中。 AlphaStar 星际争霸 2 的人机大战吸引了人工智能领域里很多专业人士的关注,它对于 AI 技术的发展会有什么样的启示。比赛过后,Facebook 研究科学家田渊栋在知乎上表示: 昨天晚上抽空看了一下 DM 的 demonstration 还有 live 的比赛。确实做得很好。 我星际水平很烂,星际 2 也玩得不多,相信大家已经看到了大量的游戏评论,我就跳过了。 整个系统和 AlphaGo 第一版很接近,都是先用监督学习学会一个相当不错的策略,然后用自对弈(self-play)加强。当然有两个关键的不同点,其一是自对弈用的是 population-based 以防止掉进局部解(他们之前在 Quake 3 上也用到了);其二是在 network 里面加了一些最近发表的神经网络模型,以加强 AI 对于游戏全局和历史长程关联性的建模能力(比如说用 transformer,比如说让 AI 可以一下子看到全部可见区域),这两点对于不完全信息游戏来说是至关重要的,因为不完全信息游戏只能通过点滴的历史积累来估计出当前的状态,尤其是对手的状态,多一点历史记录就能学得更好些,这个我们做过一些即时战略游戏(MiniRTS)的研究,很有体会。 (责任编辑:波少) |