AlphaStar称霸星际争霸2!AI再创史诗级胜利时刻(2)
时间:2019-02-14 13:09 来源:百度新闻 作者:巧天工 点击:次
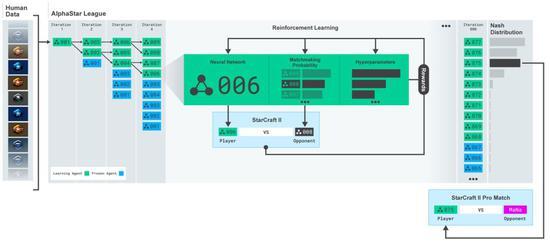
AlphaStar的行为是由一个深层神经网络生成的,该网络接收来自原始游戏interface的输入数据(单元及其属性的列表),并输出构成游戏内操作的指令序列。更具体地说,神经网络体系结构对单元应用一个转换器躯干,结合一个LSTM核心、一个带有指针网络的自回归策略头和一个集中的值基线。 DeepMind相信,这种先进的模型将有助于解决机器学习研究中涉及长期序列建模和大输出空间(如翻译、语言建模和视觉表示)的许多其他挑战。 AlphaStar还使用了一种新的多智能体学习算法。神经网络最初是由暴雪公司发布的匿名人类游戏中的监督学习训练出来的。这使得AlphaStar能够通过模仿StarCraft ladder上玩家使用的基本微观和宏观策略。这个最初的代理在95%的游戏中击败了内置的“精英”AI关卡――即人类玩家的黄金关卡。
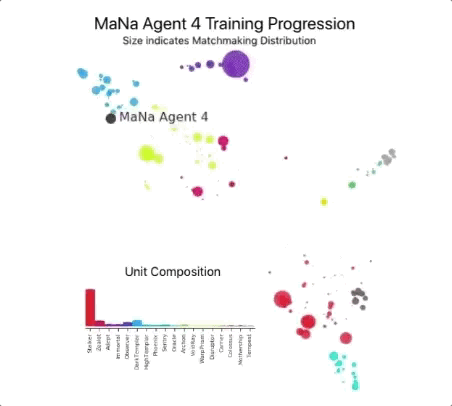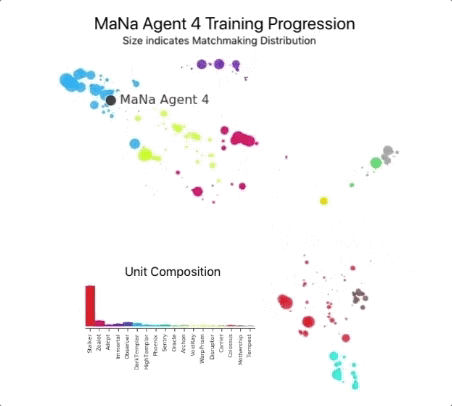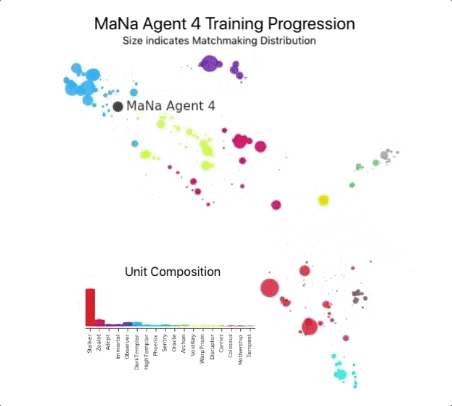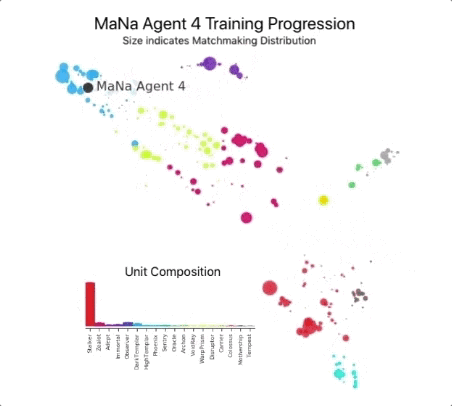
然后用它们来建立一个多主体强化学习过程。一个连续的联盟被创造出来,联盟的代理――竞争者――相互之间玩游戏,就像人类在StarCraft ladder玩游戏一样。 新的竞争者通过从现有竞争者中进行分支,动态地添加到联盟中;然后每个代理从与其他竞争对手的游戏中学习。这种新的训练形式将基于人群的强化学习理念进一步发扬光大,创造了一个不断探索《星际争霸》游戏玩法巨大战略空间的过程,同时确保每个竞争对手都能在最强的战略面前表现出色,并且不会忘记如何击败较早的战略。
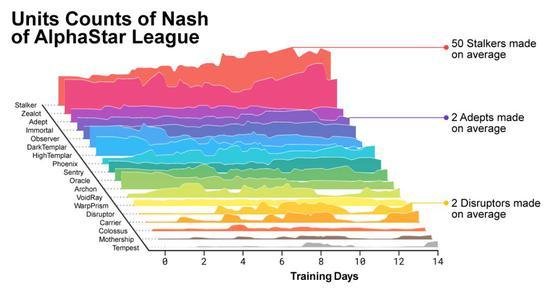
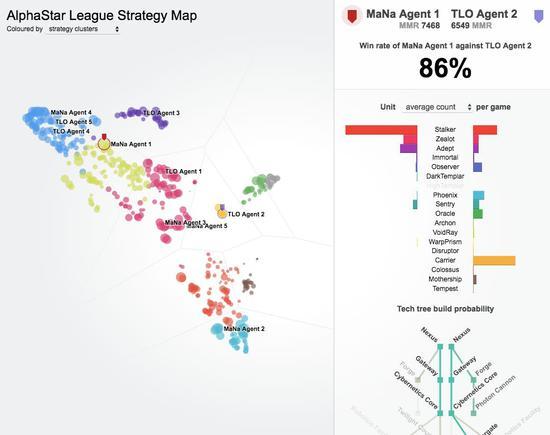
随着联赛的发展和新的竞争对手的产生,新的对抗策略出现了,能够击败以前的策略。当一些新的竞争者执行一个仅仅是对以前的策略的改进的策略时,另一些人发现了包含全新构建订单、单元组合和微观管理计划的全新策略。 例如,在AlphaStar联盟早期,一些“俗套”的策略,如使用光子炮或黑暗圣堂武士进行非常快速的快攻,受到了玩家的青睐。随着训练的进行,这些冒险的策略被抛弃了,产生了其他的策略:例如,通过过度扩张拥有更多工人的基地来获得经济实力,或者牺牲两个神谕来破坏对手的工人和经济。这一过程类似于《星际争霸》发行多年以来玩家发现新策略并能够击败之前所青睐的方法的过程。
为了鼓励联盟的多样性,每个代理都有自己的学习目标:例如,这个代理的目标应该是打败哪些竞争对手,以及影响代理如何发挥的任何其他内部动机。一个代理可能有打败某个特定竞争对手的目标,而另一个代理可能必须打败整个竞争对手分布,但这是通过构建更多特定的游戏单元来实现的。这些学习目标在培训过程中得到了调整。
最好的结果可能是通过手工制作系统的主要元素,对游戏规则施加重大限制,赋予系统超人的能力,或者在简化的地图上进行游戏。即使有了这些改进,也没有一个系统能与职业选手的技术相媲美。相比之下,AlphaStar在星际争霸2中玩的是完整的游戏,它使用的深度神经网络是通过监督学习和强化学习直接从原始游戏数据中训练出来的。
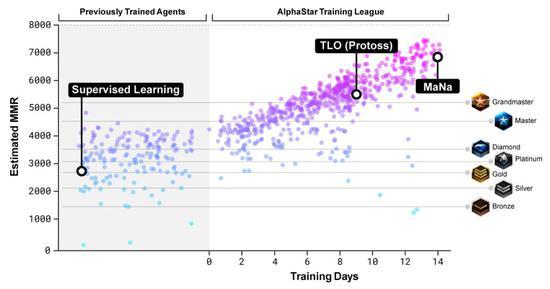
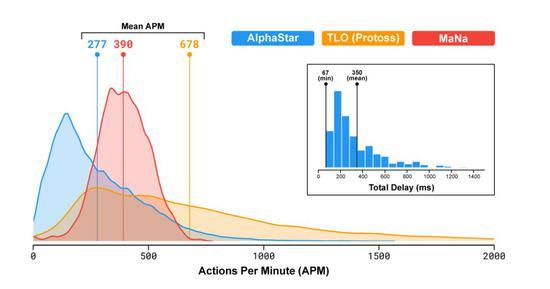
为了训练AlphaStar,DeepMind使用谷歌的v3版本的TPU构建了一个高度可伸缩的分布式训练设置,它支持大量代理从数以千计的星际争霸2并行实例中学习。AlphaStar联赛运行了14天,每个代理使用16个TPU。在训练期间,每个代理都经历了长达200年的星际争霸实时游戏。最终的AlphaStar代理由联盟的Nash分布组成――换句话说,已经发现的最有效的策略组合――运行在单个桌面GPU上。 另外,这项工作的论文也即将发布。 AlphaStar实战技巧分析 讲完AlphaStar的训练过程,再来分析下实战过程。 像TLO和MaNa这样的职业星际争霸玩家,平均每分钟可以做数百个操作(APM)。这远远少于大多数现有的机器人,它们独立控制每个单元,并始终保持数千甚至数万个APM。 在与TLO和MaNa的比赛中,AlphaStar的平均APM约为280,远低于职业选手,不过它的动作可能更精确。 造成APM较低的部分原因是AlphaStar使用回放开始训练,因此模仿了人类玩游戏的方式。此外,AlphaStar的反应在观察和行动之间的平均延迟350ms。
在与TLO和MaNa对弈过程中,AlphaStar通过原始界面与星际争霸2引擎连接,这就意味着它可以直接在地图上观察自己的属性和对手的可见单位,而无需移动相机。 相比之下,人类玩家必须明确管理“注意力经济(economy of attention)”,并决定在哪里对焦相机。
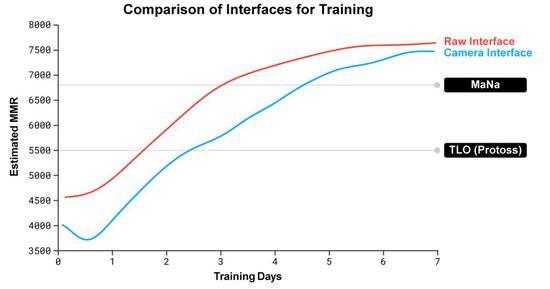
然而,对AlphaStar游戏的分析表明,它管理着一种隐性的注意力焦点。平均而言,智能体每分钟“切换内容”约30次,类似于MaNa或TLO的操作。 此外,在比赛之后,DeepMind还开发了AlphaStar的第二个版本。和人类玩家一样,这个版本的AlphaStar会选择何时何地移动摄像头,它的感知仅限于屏幕上的信息,行动地点也仅限于它的可视区域。 DeepMind训练了两个新智能体,一个使用raw interface,另一名必须学会控制摄像头,以对抗AlphaStar League。 每个智能体最初都是通过从人类数据中进行监督学习,然后按照强化学习过程进行训练的。使用摄像头界面的AlphaStar版本几乎和raw interface一样强大,在DeepMind内部排行榜上超过了7000 MMR。 在表演赛中,MaNa用camera interface击败了AlphaStar的一个原型版本,这个interface只训练了7天。 这些结果表明,AlphaStar对MaNa和TLO的成功实际上是由于优越的宏观和微观战略决策,而不是快速的操作、更快的反应时间或raw interface。 人类挑战20年,AI攻下星际争霸有五大困难 (责任编辑:波少) |