星际2职业高手首次被AI击溃,AlphaStar一战成名(2)
时间:2019-02-17 15:07 来源:百度新闻 作者:巧天工 点击:次
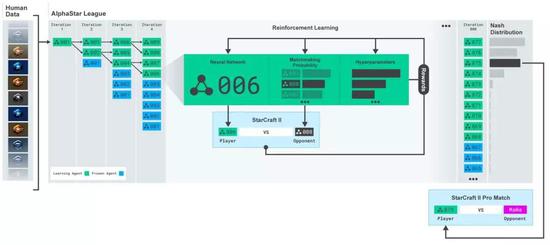
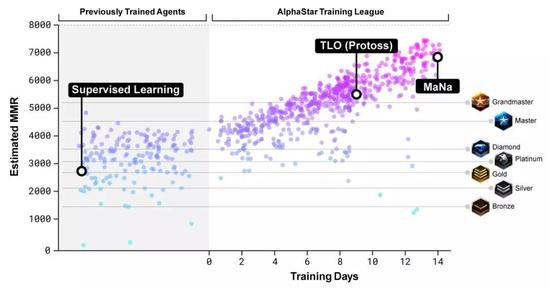
AlphaStar还用了一个新的多智能体学习算法。 这个神经网络,经过了监督学习和强化学习的训练。 最开始,训练用的是监督学习,素材来自暴雪发布的匿名人类玩家的游戏实况。 这些资料可以让AlphaStar通过模仿星际天梯选手的操作,来学习游戏的宏观和微观策略。 最初的智能体,游戏内置的精英级 (Elite) AI就能击败,相当于人类的黄金段位 (95%) 。 而这个早期的智能体,就是强化学习的种子。
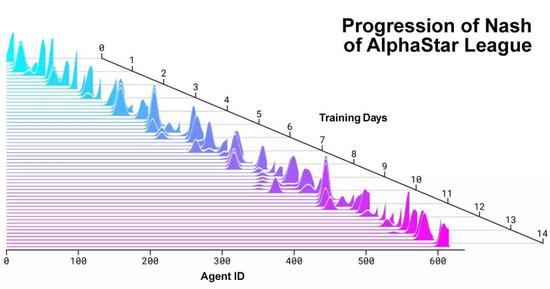
在它的基础之上,一个连续联赛 (Continuous League) 被创建出来,相当于为智能体准备了一个竞技场,里面的智能体互为竞争对手,就好像人类在天梯上互相较量一样: 从现有的智能体上造出新的分支,就会有越来越多的选手不断加入比赛。新的智能体再从与对手的竞争中学习。 这种新的训练形式,是把从前基于种群 (Population-Based) 的强化学习思路又深化了一些,制造出一种可以对巨大的策略空间进行持续探索的过程。 这个方法,在保证智能体在策略强大的对手面前表现优秀的同时,也不忘怎样应对不那么强大的早期对手。
随着智能体联赛不断进行,新智能体的出生,就会出现新的反击策略 (Counter Strategies) ,来应对早期的游戏策略。 一部分新智能体执行的策略,只是早期策略稍稍改进后的版本;而另一部分智能体,可以探索出全新的策略,完全不同的建造顺序,完全不同的单位组合,完全不同的微观微操方法。 早期的联赛里,一些俗气的策略很受欢迎,比如用光子炮和暗黑圣堂武士快速rush。 这些风险很高的策略,在训练过程中就被逐渐抛弃了。同时,智能体会学到一些新策略;比如通过增加工人来增加经济,或者牺牲两个先知来来破坏对方的经济。 这个过程就像人类选手,从星际争霸诞生的那年起,不断学到新的策略,摒弃旧的策略,直到如今。 除此之外,要鼓励联赛中智能体的多样性,所以每个智能体都有不同的学习目标:比如一个智能体的目标应该设定成打击哪些对手,比如该用哪些内部动机来影响一个智能体的偏好。 而且,智能体的学习目标会适应环境不断改变。
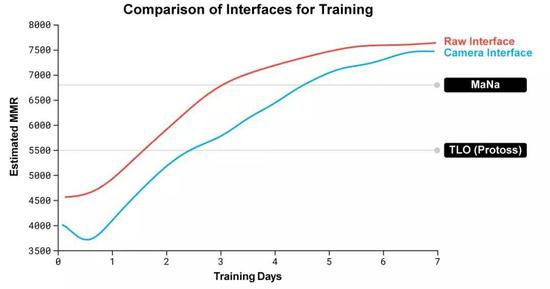
神经网络给每一个智能体的权重,也是随着强化学习过程不断变化的。而不断变化的权重,就是学习目标演化的依据。 权重更新的规则,是一个新的off-policy演员评论家强化学习算法,里面包含了经验重播 (Experience Replay) ,自我模仿学习 (Self-Imitation Learning) 以及策略蒸馏 (Policy Distillation) 等等机制。 为了训练AlphaStar,DeepMind用谷歌三代TPU搭建了一个高度可扩展的分布式训练环境,支持许多个智能体一起从几千个星际2的并行实例中学习。每个智能体用了16个TPU。 智能体联赛进行了14天,这相当于让每一个智能体都经历了连打200年游戏的训练时间。 最终的AlphaStar智能体,是联赛中所有智能体的策略最有效的融合,并且只要一台普通的台式机,一块普通的GPU就能跑。 AlphaStar打游戏的时候,在看什么、想什么?
上图,就是DeepMind展示的AI打游戏过程。 原始的观察里数据输入到神经网络之中,产生一些内部激活,这些激活会转化成初步的决策:该做哪些操作、点击什么位置、在哪建造建筑等等。另外,神经网络还会预测各种操作会导致的结果。 AlphaStar看到的游戏界面,和我们打游戏时看到的小地图差不多:一个小型完整地图,能看到自己在地图上的所有单位、以及敌方所有可见单位。 这和人类相比有一点点优势。人类在打游戏的时候,要明确地合理分配注意力,来决定到底要看哪一片区域。
不过,DeepMind对AlphaStar游戏数据的分析显示,它观察地图时也有类似于人类的注意力切换,会平均每分钟切换30词左右关注的区域。 这,是12月打的10场游戏的情况。 今天直播中和MaNa对战的AI,就略有不同。 (责任编辑:波少) |