FTL那些事2 Hot/Cold Data
时间:2019-02-21 13:11 来源:百度新闻 作者:巧天工 点击:次
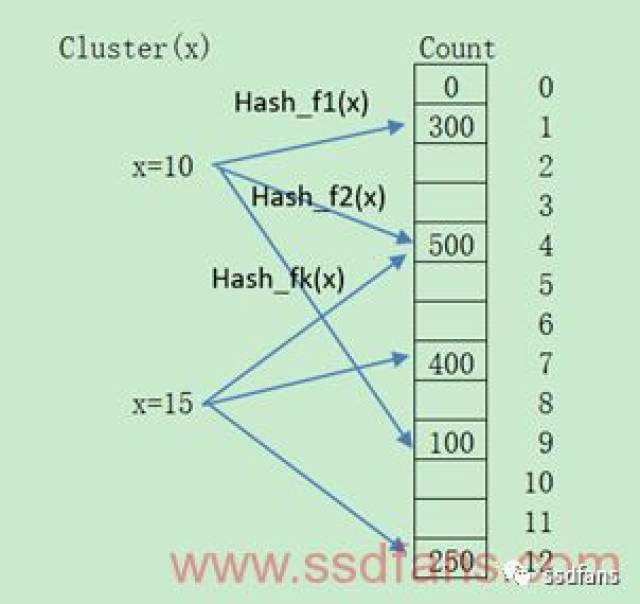
那么这个和Hot/Cold Data识别有什么样的联系呢?这就是善于学习举一反三的人类的厉害之处,有如下三种方法: Count计数法: 该方法针对Bloom Filter的改动很简单,将Bit换成是Count,当被Hash函数映射到某个Bit时候,对应的Count就进行加1,那么从频率上看Hot/Cold,就从某个Cluster的所有映射计数是否超过预设阈值,超过则认为是Hot。如下图所示:
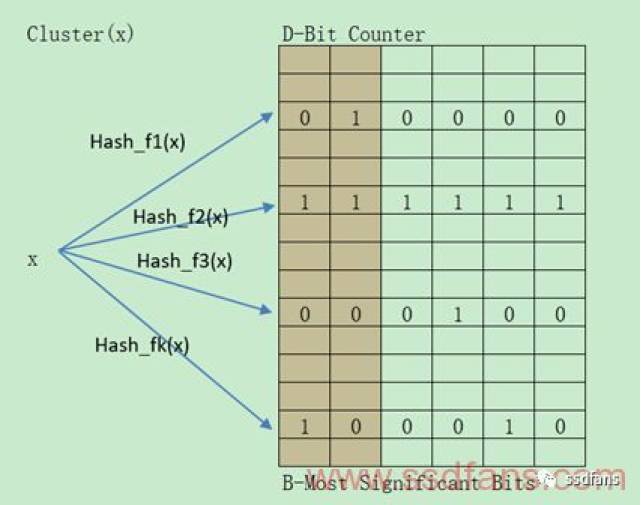
One Bloom Filter With D-Bit Counter: 这个可以认为是方法(1)的另一种表述,毕竟默认Count变量会占有的Bit数很多,因此用D-Bit Counter表示。但是并非仅此而已,它会每隔一段时间对D-Bit Counter做一次退化操作,右移一位。并且设有最左边2个Bit作为B-Most Significant Bits,该Bits里面只要含1且所有Hash函数映射的都是B-Most Significant Bits中含1,就认为是Hot Data。该种方法依然只能获得最频繁的信息而得不到最近使用的信息。具体如下图所示:
Multiple Bloom Filters(MBF): 针对上述不能获得最近使用的信息,MBF改进了这一点。它设定了V个BF,从频率上看,如果Cluster(x)经过K个Hash函数映射的K个Bit在V个BF里全为1则认为是Hot Data;从时间上看,出现在V个BF中第几个,最大的则是最近出现的,如果时间间隔T,未被选中的BF将被选中并Reset成0。具体映射步骤如下:Cluster经过K个Hash函数映射的K个Bit在某个BF已经写了,则写下一个,直到V个BF写完,没有新的BF映射或者达到某个阈值则可以被认为是Hot Data,;通过设定连续个Write数目作为检查条件来代替时间间隔T,首次为BFv,循环Reset下一个BFi为全0。BF的Bit数目M计算条件为M=KN/ln2,其中K为Hash函数个数,N为Cluster个数;退化周期T=M/V,其中V为BF个数,实际上T可以用连续Write数目替代。该种方法可以获得细粒度的最新使用信息,低运行Overhead,低Memory消耗。如下图所示:
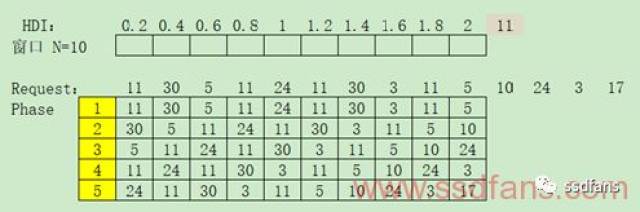
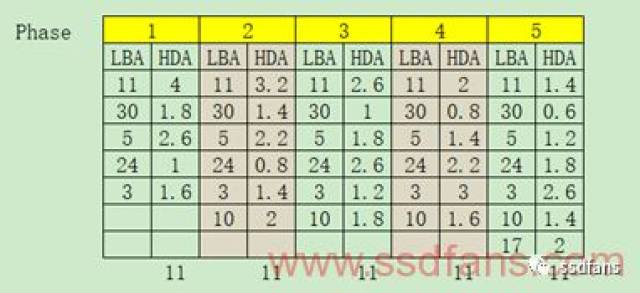
WDAC WDAC全称是Window-based Direct Address Counting,关于时空频率的相对简单Hot Data计算方法,能够获得较为精确的最近频率信息,具体步骤如下: 类似WDAC,早在Robert G..Brown就提出了指数平滑法(Exponential Smoothing),认为时间序列的态势具有稳定性或规则性,最近的过去态势在某种程度上持续到最近的未来,所以将较大的权数放在最近的资料上,预测值是以前观测值的加权和,且对不同的数据给予不同的权数,新数据给予较大的权数,旧数据给予较小的权数。根据指数平滑次数不同分为一次指数平滑法、二次指数平滑法和三次指数平滑法等。以一次指数平滑法为例,estr(Tn) = k*Xn + (1-k)*estr(Tn-1),其中k是平滑常数,取值范围[0, 1],Xn是Tn的观察值,当Tn访问时候Xn=1,否则Xn=0,extr(Tn-1)是Tn-1时候平滑值。还以WDAC例子来说明,如下图所示,当k=0.5且预测参数FCST>0.1时,只有LBA 11被命中3次:
由此可见需要调节的参数有k值和FCST判断,重要的是FCST判断,在具体工程上要根据缓存的大小要进行取舍。假设当前缓存有M个,那么将计算的LBA访问的指数平滑结果从大到小排序,选择第1到M个为预测LBA。 设定一个大小为N的窗口,并将窗口每个元素设定相应权重HDI,比如下图:
滑动窗口,并计算其元素的HDI总和,比如上述设定结果如下:
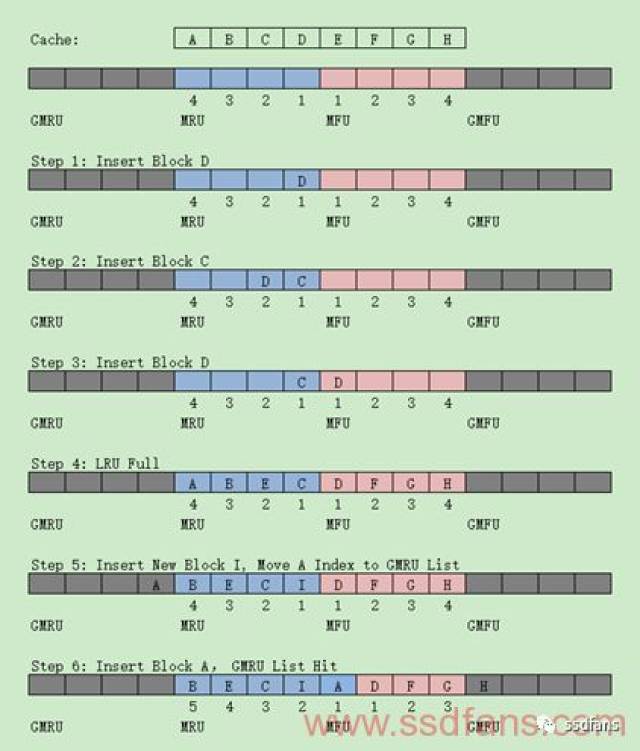
LRU 从前面一节Mapping就可以发现LRU(最近最少使用)被应用的相当广泛,而且被演化的算法也众多。比如基本的LRU具有很好的时间特性,增加频率计数的LRU-K,LRU-2Q,LRU-MQ,LRFU,ARC,BPLRU等。下面将简要介绍相关LRU算法: LRU-2(或LRU-K) LRU-K是多维护一个队列,用于记录所缓存数据的访问历史,当某个缓存数据访问次数达到K时,才将数据缓存。当淘汰数据时,会淘汰第K次访问时间距当前时间最大的数据,所留下来的数据可认为是Hot Data。 LRFU(Least Recently/Frequently Used) 顾名思义融合了时间和频率特征,为每个缓存项维护一个权值,其初始值为0,用以表示该块继续被访问的可能性,除此之外还记录上次访问时间。缓存管理器维护与权值相关的堆,选择最小的权值作为堆的根节点,插入和更新都可以根据堆来调整,而淘汰时直接拿根节点置换即可。权值的设定类似WDAC做法。但是该算法值固定,无法满足访问模式的变化,不能做出相应的自适应处理而性能下降。 因此ALRFU(Adaptive LRFU)被提出,通过监控访问历史,动态调整权值来适应数据访问模式发改变。 2Q(或MQ) 2Q类似于LRU-2的做法,只是2Q将LRU-2缓存访问历史LRU队列改为缓存数据FIFO队列,另一个缓存数据的LRU队列仍然保留。新访问的数据插入到FIFO队列,如果在FIFO队列里面数据一直没被访问,则按照FIFO规则淘汰,如果FIFO队列数据再一次访问则将数据移到LRU队列头,LRU队列再次访问也会放到LRU队列头部,LRU队列按照LRU规则淘汰队尾数据。 MQ根据访问频率划分为多个队列,每个队列都按照LRU进行管理,不同队列设置不同的优先级,而数据优先级根据访问次数计算得来,访问每达到预设次数就提升优先级,而当数据在指定时间未被访问则会降低优先级,淘汰数据则从最低优先级开始淘汰。 ARC ARC是一个自适应的有效的LRU算法,ARC叫法有很多,IBM有一套叫Adaptive Replacement Cache算法,ZFS有一套叫Adjust Replacement Cache,大家讲的具体请参考文献:A self-tuning, low overhead replacement cache。思想是根据负载自动调整的策略,并集合了LRU和LFU的优点,它定义了4个链表,分别是: 最近最多使用链表MRU List 最近最常使用链表MFU List 存储从MRU List淘汰的信息(Ghost List for MRU)GMRU List 存储从MFU List淘汰的信息(Ghost List for MFU)GMFU List 并根据GMRU和GMFU命中情况动态调整MRU和MFU List大小。操作步骤如下图所示:
|