“最终之战”人类完败!DOTA2 AI 2:0吊打世界冠军,“人类再打5(3)
时间:2019-05-01 00:36 来源:百度新闻 作者:巧天工 点击:次
AI 作弊争议背后的本质问题是:人类和 AI 之间可能有所谓“公平”的博弈吗?恐怕我们等不到这样一场比赛了。因为,AI 天生就被按照比人类有优势来打造。正如 AI 游戏研究员库克所说的那样:“计算机当然要在某些方面比人类优秀。这是我们发明计算机的原因。”
图 | “眼观三十六路,耳听四十八方”的AI(来源:OpenAI) 在游戏中击败专业人士,也不是 OpenAI 等公司开发游戏 AI 所追求的目标。他们所希望的,是 AI 学习如何制定数以千计的小决策来实现更大的目标。Brockman 曾这样表示:“我们 Dota 项目的初衷不是为了在这个比赛称霸,是因为我们认为可以开发出能够在未来几十年内为世界提供动力的人工智能技术。”对于 OpenAI 来说,选择 DOTA2 作为人工智能测试的原因,“是因为我们认为它是一个能够帮助我们测试和开发通用 AI 技术的良好平台”。 而且,这个雄心勃勃的想法也正在走向现实。例如,用于教授 OpenAI Five 的“基础设施”之一――一个名为 Rapid 的系统就正在被用于其他项目,例如用它来使机械臂以更高水平的灵活性来操纵物体。另外,该系统可以协调数千个同时运行数百个强化学习算法的处理器,每个算法都为机器人提供动力,机器人通过游戏或模拟移动手,然后在试验结束时将其学到的内容与其他机器人同步。Rapid 目前仍在持续改进中。 图丨 Rapid 系统被用到机械手操控上(来源:OpenAI) 另一方面,AI 在 Dota2 中有胜有败的表现,也让人们继续反思相关的技术方向,强化学习是其中讨论度最高的话题之一。 OpenAI 创建人工智能时使用了强化学习算法。这种被认为可以实现让机器“从零开始学习”的技术看似简单,但是能让 AI 习得一些复杂的行为。它有别于传统的监督学习,不需要大量的标注数据,让 AI 在虚拟环境中通过自我尝试和奖励学会复杂的任务。对于游戏这种拥有天然优秀的模拟环境的场景,强化学习被认为可以帮助创造水平极高的游戏 AI。
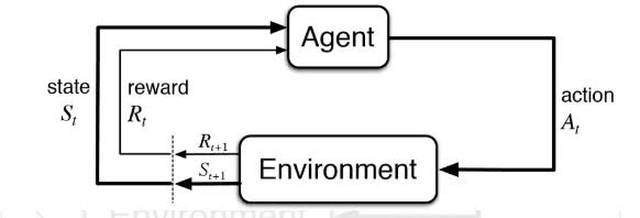
图丨强化学习的原理(来源:thegradient.pub) 强化学习最出风头的案例,恐怕还是 Deepmind 开发 AlphaGo 的一战成名,尤其是 AlphaGo Zero 的诞生。两者都是强化学习发展史上里程碑式的案例。AlphaGo 结合了监督学习、强化学习和其他一些创新的辅助方法,而 AlphaGo Zero 仅仅依靠强化学习和自我对弈,尽管它也使用了预先准备的算法规则用于持续的迭代,依然比前者更遵循了强化学习的整体思路。但著名 AI 学者、新晋图灵奖获得者 Yann LeCun 认为,AlphaGo Zero 的成功很难推广到其他领域。 在 OpenAI Five 被职业队打败的过程中,AI 充分暴露了依靠这种方法抛弃人类先验经验、获取新的技能,还有一些“盲区”。 来自斯坦福的 Andrey Kurenkov 就撰写了大量有关强化学习局限性的文章,他表示,此前的比赛表明,强化学习可以处理“比大多数人工智能研究人员想象的复杂程度更高的问题”,但一些失败的结局表明,游戏 AI 需要新的方式来培养其“长期思维”。也就是说,AI 在即时即地的反应上做得很好,但宏观层面决策的表现却很糟糕。他在其文章中如此总结 AlphaGo 和 OpenAI Dota2 AI 的成绩局限性所在:从零开始学习导致它们和人类学习相比,更依海量游戏指令和使用更原始的、无人能及的计算能力。 也正因为这些局限,目前我们也还没有看到有任何 AI 被广泛应用在商业级游戏中。但在接下来很长一段时间,AI 打游戏恐怕还需要通过强化学习来实现,强化学习究竟是不是让机器能够像人一样从零学习新技能的最佳方法,还需要更长时间的验证。
(来源:WIKIMEDIA COMMONS) -End- 坐标:北京・国贸 请随简历附上3篇往期作品(实习生除外)
2018全新换装养成手游,撩翻你的少女心 (责任编辑:波少) |