AI吊打DOTA2人类高手?你可能又被标题党坑了(2)
时间:2019-05-29 16:22 来源:百度新闻 作者:巧天工 点击:次
通用游戏AI竞赛中的十多款Atari游戏都属于完全信息博弈。在这些游戏中,复杂度最高的几款游戏AI仍达不到击败人类玩家的水平。而在其余的一些规则相对简单的游戏中(如《乓》和《太空侵略者》游戏),人类玩家已经远不是AI的对手。 在这些游戏中,AI是如何被开发并优化,一步步击败人类的呢? 目前比较流行的通用游戏AI训练方式是以2013年NIPS上发表的,关于深度Q网络(Deep Q-Learning Network , DQN)为基础的强化学习(Reinforcement Learning)和深度神经网络(Deep Neural Network,DNN)的结合。下面两篇文献中有详细的解释,这里仅以《乓》为例做简要介绍。 ·Playing Atari with Deep Reinforcement Learning. ArXiv (2013) ·Human-level control through deep reinforcement learning. Nature (2015) 首先,简要介绍一下啥叫强化学习和深度神经网络。 强化学习(Reinforcement Learning)是机器人(可以理解为AI)在与环境交互中,根据获得的奖励或惩罚,不断进行学习的一种机器学习方式。
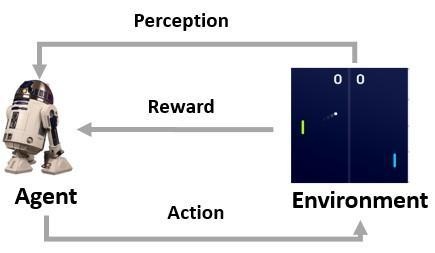
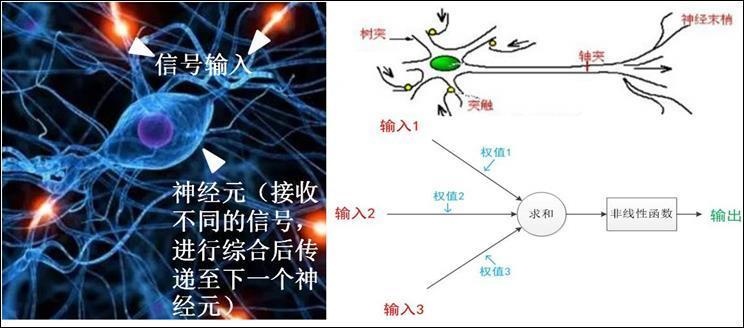
(强化学习示意图) 如图所示,从环境中,机器人会不断地得到状态(State) 和奖励(Reward)。这与动物学习非常类似。一开始,机器人不知道环境会对不同行为做出什么样的反应,仅从环境中获取观察的状态,这就是最上方箭头表示的感知(Perception)。而环境能够根据机器人的行为反馈给它一个奖励。 例如在《乓》中,向上移动回击小球,如对手没接住就分会增加一分,那么这一步的奖励就是正值;反之,奖励为负值。重复感知、行动和奖励的过程就形成一个强化学习的交互流程,AI在这种交互中不断纠正自己的行为,从而对环境变化做出最佳的应对。 深度神经网络(Deep Neural Network,DNN),也被称为深度学习,其产生来源于科学家们模拟人脑中神经元之间传递信号的方法开发出的机器学习技术(所以才叫人工智能啊喂)。 众所周知,人脑中神经网络由1000亿多个神经元(即神经细胞)构成,不同神经元之间通过突触结构彼此相连。在这之中,每个神经元需要接收来自不同数个临近神经元传来的信号(输入1,输入2,输入3……),进行整合(后最终被传播到“输出层”,将神经网络的最终结果输出给用户。 由此可见,神经元的计算对数据的识别、处理(加权)及最终输出具有至关重要的作用,在计算机领域,这个中间步骤被称为网络的“隐藏层”。
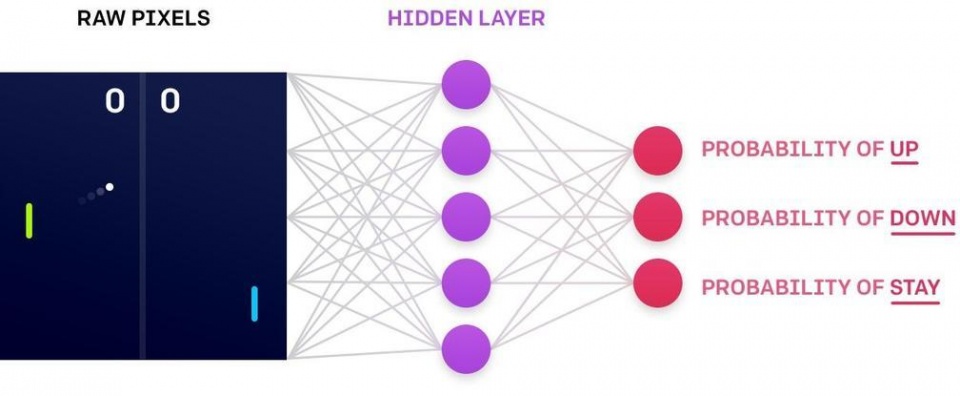
(神经元/深度神经网络工作原理,图片来自网络) 深度神经网络与强化学习的联合应用,即是深度Q网络模型(深度强化学习)。例如,在《乓》中深度Q网络的简略流程:输入游戏原始画面,经过隐藏层加权后会输出概率动作输出空间。例如,在《乓》中选择上移(Up)、下移(Down)和不动(Stay)的概率。
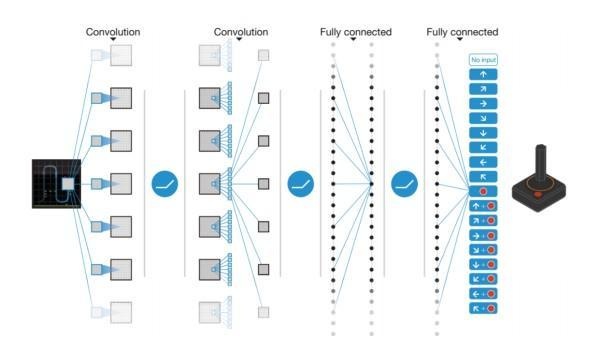
(深度Q网络流程图(图片来自)) 又如,Deepmind在2013年提出的一个更为复杂的深度Q网络网络结构。输入是连续4帧游戏原始画面,输出是不同动作的长期化收益Q,中间为两个卷积层(Convolutional Layer)和两个全连接层(Fully Connected Layer)。
(DQN网络结构图(图片来自)) 我们再回到开头,看一下这次Dota2的人机对抗视频。比赛距今已约两周的时间,OpenAI最终公布了Dota AI的一些比赛细节,不过还是有所保留,并未公布全部的技术细节,不过我们可以从公开消息中猜测一二: 1. Dota是不完全信息博弈,玩家并不能直观获得对手的位置和活动信息。这使得每一步的决策都是在具有不确定性的条件下做出的。 2. AI机器人并不能局限于仅提供类似“向上移动”这样的微观操作。必须把微观操作转换连续的宏观动作流程,就像比赛视频中的卡兵操作。 3. Dota是多机器人(multi-agent)合作博弈,这是当前AI领域最具有挑战性的部分。 4. 合理的分配、使用道具,这涉及到长期的规划策略。 OpenAI Bot选择了1v1的对抗模式,简化其有效动作数(available actions)和有效状态空间(state space)数。在该限制条件下,对抗的关键为技能选择和短期策略,并不涉及到长期规划和多机器人协调。也就是说对战环境的设置更加类似于《街霸》一类的格斗游戏,而不是真正的即时战略。
(一些可能的AI输入信息) 值得注意的是,如果将游戏设置为即时战略(RTS)模式,从目前来看,就算在OepnAI的限制场景下, OpenAI Bot还未达吊打人类的水平。由于算法鲁棒性和泛化能力的局限性,它还无法像人类玩家一样从若干几回合的对局中找到对手弱点并加以针对。就像Deepmind在开源的星际2人工智能学习环境(SC2LE)中指出的那样,现阶段,AI还不具备在即时战略(RTS)游戏中对抗人类玩家的能力。
(OpenAI Bot被战翻50余次) 从传统的棋牌类游戏(象棋、围棋、德州扑克)到经典对战电子游戏(星际、Dota、CS),AI在征服了几乎全部的棋牌类游戏之后,又将魔爪伸向了即时战略游戏。人类还能在多大程度上延缓AI的攻势,即时战略游戏何时才会全面沦陷?非完全信息博弈游戏集中体现了人类智慧的高度,如同两国交战,战术和战略层面的种种策略——诱敌深入、千里奔袭、围魏救赵、擒贼擒王、声东击西、瞒天过海……都可以在Dota以及CS中找到对应的影子。 如果有一天,AI也能产生“谋略”,像人类一样运筹帷幄、纵横捭阖,类似电影《终结者》系列中拥有自主智能并致力于绞杀人类的AI“天网”可能绝非狂想。在不断提升AI性能、应用领域的同时,人类还需不断的思考人工智能的发展方向以及人类与人工智能的未来。 |