Dota2败给OpenAI-Five究竟是为什么?
时间:2019-06-04 06:26 来源:百度新闻 作者:巧天工 点击:次
OpenAI昨日发布研究成果,宣布Dota2 5v5在限定条件下(英雄阵容固定,部分道具和功能禁用)战胜人类半职业选手。本文主要对其模型技术架构做一些分析总结。 一、 模型输入与输出模型的输入是使用RAM(内存信息),如位置坐标,技能血量数值状态等,而不是图像像素信息。
模型输入主要分为两个部分: 直接观测的信息:场面其他英雄的绝对位置,相对距离,相对角度,血量,状态等。 人工定义抽象的信息:是否被攻击以及正在被谁攻击,炮弹距离命中的时间,朝向的cos与sin,最近12帧内的英雄的血量变化等。 模型的输出即是指AI所选择的动作,包括移动,攻击释放技能等。OpenAI将连续的动作,离散化对应到网格,并对各种技能定制化释放动作,以减少动作空间的大小。以下图为例,AI要释放一个攻击技能,需要选取这个技能,并选择一个目标单位周围网格内的一个位置:
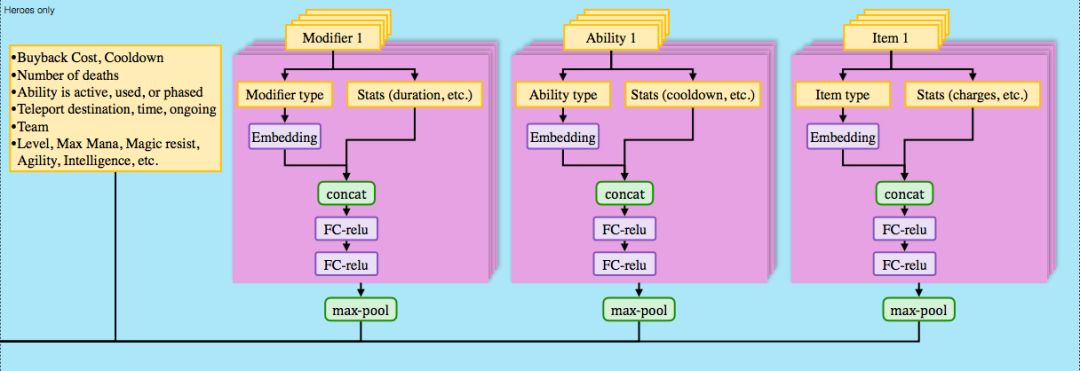
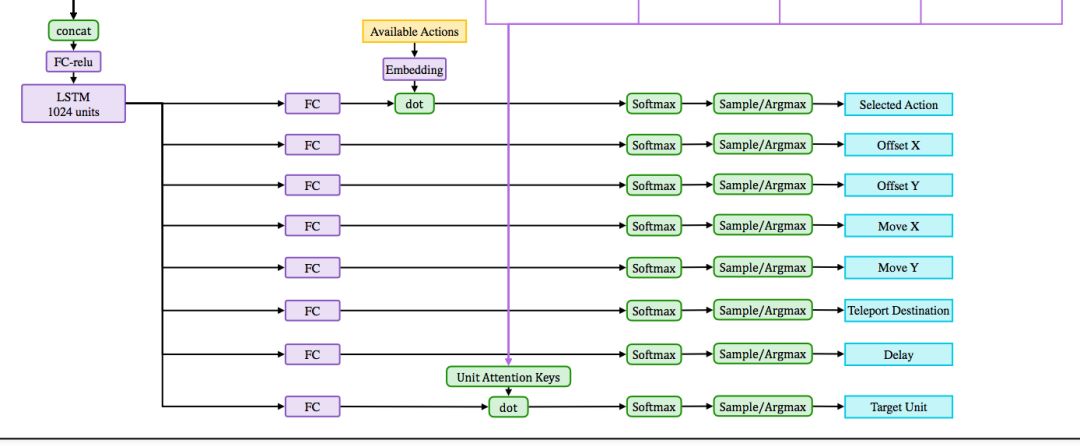
值得注意的是,在Dota2游戏内还有其他动作,例如操控信使,购买装备,技能升级与天赋等,这些都是人工定义好,而不需AI决策的。而操控幻象分身,召唤物等涉及更复杂的多单位操作,则未在OpenAI当前版本的考虑范围内。 二、 网络架构与训练方式网络架构架构局部如下图:
模型大图下载链接:https://d4mucfpksywv.cloudfront.net/research-covers/openai-five/network-architecture.pdf 总的来看,大量信息通过连接(concatenate)与全连接层(dense)层进行综合,作为1024维的LSTM的输入。LSTM综合时序信息,并输出决策向量,再用决策向量解构出详细动作。 训练方式: 纯自我对弈训练。 随机化训练:随机初始状态(血量速度移动等)的训练,以增强泛化能力。 使用很高的γ=0.9997。γ为奖励衰减值,一般在其他环境中设置为0.98,0.998。 大量计算:128,000CPU+256GPU,能做到每天模拟玩180年的游戏。 奖励(reward)设计: 总体奖励:当前局面评估(塔的情况等),KDA(个人战绩),补兵表现等。 合作奖励:全队的表现作为自己奖励的一部分。 分路对线的奖励与惩罚:最开始分配一条路,前期发育时如果偏离就会惩罚。 三、 总结用强化学习玩Dota2需要面对4个挑战:状态空间大,局面不完全可见(有视野限制),动作空间大,时间尺度大。 近期论文中提出的解决方案,大致有以下几个方向: 状态空间大:解决方法如先用World Models抽象,再进行决策。 局面不完全可见:一般认为需要进行一定的搜索,如AlphaGo的MCTS(蒙特卡洛树搜索)。 动作空间大:可以使用模仿学习(Imitation Learning),或者与层次强化学习结合的方法。 时间尺度大:一般认为需要时间维度上的层次强化学习(Hierarchical Reinforcement Leanring)来解决这个问题。 而神奇的是,OpenAI没有使用上述任一方法,而仅仅使用高γ值的PPO基础算法,就解决了这些问题。这说明凭借非常大量的计算,强化学习的基础算法也能突破这些挑战。 OpenAI没有使用的WorldModels,MCTS,IL,HRL等方法,既是学术界研究的重点方向,也是OpenAI-Five潜在的提升空间。这些更高效的方法若被合理应用,可以加快模型的学习速度,增强模型的迁移能力,并帮助模型突破当前的限制。 (责任编辑:波少) |